JST CREST「共創型音メディア機能拡張」成果報告シンポジウム
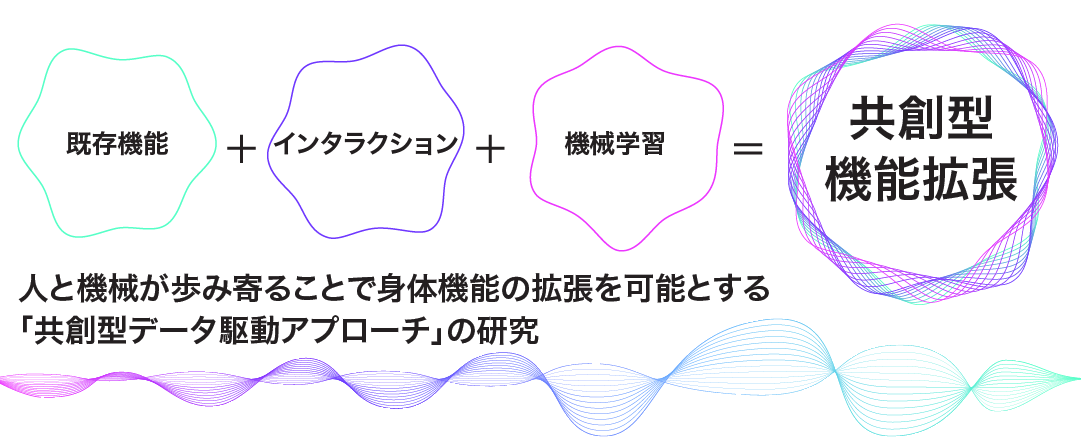

JST CREST共生インタラクション研究領域の研究課題として、5年半の期間をかけて、共創型音メディア機能拡張プロジェクトに取り組んでまいりました。その結果、本プロジェクトで取り組んできた研究課題について、数多くの研究成果が得られました。これらの研究成果を皆様と共有させて頂く場として、CREST共創型音メディア機能拡張成果報告シンポジウムを開催することに致しました。本シンポジウムを通しまして、今後さらなる研究の発展に向けて、ご参加頂く皆様同士の交流、本プロジェクトメンバーとの交流ができる場になればと願っています。
研究代表者 戸田 智基


日時 :2025年3月27日(木)10:00-17:00
会場 :名古屋大学 工学研究科 EI創発工学館ホール2階
アクセス:地下鉄名城線 名古屋大学駅 2番出口より徒歩4分(google map)
参加登録:本シンポジウムへの参加は無料ですが、下記から事前登録が必要です。

事前登録
参加を予定されている方は、下記のリンクより3月25日までに事前登録をお願いいたします。

本シンポジウムでは、まず、研究代表者と2名の研究分担者が、JST CREST「共創型音メディア機能拡張」プロジェクトの研究成果を紹介する登壇発表を行います。その後、昼休憩をはさみまして、本プロジェクトメンバーが各種研究成果についてポスター発表およびデモ展示を行います。最後には、Academia Sinica(台湾)のYu Tsao教授をお招きして、音声評価技術に関する招待講演を行って頂きます。


.png)
.png)




セッション1(13:00-14:00)
01 PRVAE-VC+iSTFTNet: iPhone上でのリアルタイム音声変換
田中 宏(NTT)
03 Save the Voiceプロジェクトおよび疑似電気喉頭音声コーパス
小林 和弘(名大)
05 Sound environment controllable voice conversion
Yeonjong Choi(名大)
07 エイリアシングフリー設計によるニューラルボコーダの性能ボトルネック改善
米山 怜於(名大)
09 歌声合成を利用した斉唱の音響特徴分析と斉唱分離への応用
西澤 佳飛(代理発表:戸田)(名大)
11 倍音の振幅操作に基づく母音の無限音階化の検討
橋本 圭織(都立大)
13 音場補間のマイクロホンアレイ処理への展開
若林 佑幸(都立大)
15 補助関数型独立ベクトル分析におけるプロジェクションバックされた分離行列の直接更新
中嶋 大志(都立大)
17 プロジェクションバックされた分離ベクトルを用いた正則化に基づく音源分離の検討
小磯 心(都立大)
19 Noisy-target Trainingに基づく教師なし残響・クリッピング除去学習
藤村 拓弥(名大)
21 大規模音声主観比較評価の実現手法とその応用
安田 裕介(名大)
23 Comparative learning for speech quality assessment using contrastive learning
Cheng-Hung Hu(名大)
セッション2(14:00-15:00)
2 FastVoiceGrad: 拡散モデルとGANの組み合わせによる高品質で高速な声質変換
金子 卓弘(NTT)
4 A representation learning framework integrating text and speech representations for electrolaryngeal speech enhancement
Ding Ma(名大)
6 高齢者介護施設向け対話ロボットのための赤ちゃん声生成
宮下 敦志(名大)
8 VAE-SiFiGAN: 変分自己符号化表現に基づくSiFiGAN
荻田 健一(代理発表:米山)(名大)
10 QHARMA-GAN:準調波ARMAモデルに基づく敵対的波形生成ネットワーク
Shaowen Chen(代理発表:戸田)(名大)
12 Generalized sound field interpolation in rotation-robust microphone array signal processing
Shuming Luan(名大)
14 相対伝達関数に基づく自己音声選択を用いた頭部装着型マイクロホンアレイによるリアルタイムブラインド音源分離
風間 香伽(都立大)
16 オンライン補助関数型独立ベクトル分析への乗法更新則の導入とそれに基づく音源毎忘却係数制御の検討
増子 凱斗(都立大)
18 Unsupervised Training of Neural Network-based Virtual Microphone Estimator
Jiachen Wang(名大)
20 プロアクティブ型ディープフェイク対策のための深層電子透かし埋め込み・検出
尹 道鉉(代理発表:安田)(名大)
22 SHEET: 自動音声主観評価推定ツールキット
Wen-Chin Huang(名大)
24 XPPG-PCA: Reference-free automatic speech severity evaluation with principal components
Bence Halpern(名大)
(プログラミングは都合により変更になる場合がありますので予めご了承ください)

展示時間:15:00-15:30
来場者の方に体感して頂ける発声・聴覚機能拡張システムのデモ展示を行います。
PRVAE-VC+iSTFTNet: iPhone上でのリアルタイム音声変換
田中宏(NTT)
歌声変換によるキャラクタ歌声生成
Lester Phillip Violeta & Wen-Chin Huang(名大)
喉頭摘出者の音声再獲得に向けた発声支援
Lester Phillip Violeta & 戸田 智基(名大)
iPhone上での低遅延リアルタイムブラインド音源分離
小野 順貴(都立大)
マイクロフォンアレイの回転に頑健な音声強調
山岡 洸瑛(都立大)

- CREST共創型音メディア機能拡張プロジェクト
「音メディアコミュニケーションにおける共創型機能拡張技術の創出」
- 科学技術振興機構(JST)戦略的創造研究推進事業(CREST)
- 研究領域「人間と情報環境の共生インタラクション基盤技術の創出と展開」
- 研究代表者 戸田 智基(名古屋大学 教授)
- 研究分担者 小野 順貴(東京都立大学 教授)
- 研究分担者 亀岡 弘和(NTTコミュニケーション科学基礎研究所 上席特別研究員)
- 安田 裕介(名古屋大学 特任講師)
- Wen-Chin Huang(名古屋大学 助教)

- 名古屋大学 情報基盤センター

学術シンポジウムに参加したことがない皆様にも、是非ご参加いただければと願っておりますが、上記の説明だけでは、参加いただく上でわかりにくい点もあるかもしれません。
ご不明な点は遠慮なくcontact@crest-coaugmentation.com宛にご連絡ください。
事前登録
参加を予定されている方は、下記のリンクより3月25日までに事前登録をお願いいたします。

音メディアコミュニケーションにおける共創型機能拡張技術の創出
JST CREST「共創型音メディア機能拡張」中間シンポジウム 2022
Copyright © JST CREST CoAugmentation Project, All rights reserved.
